
AWS Solutions for Complex JSON Data Transfer from Amazon DynamoDB to Data Lake
Reading Time: 10 min
Rajan Kshirsagar

Aug 29,
2024 |
Posted in
Data & Analytics
In today’s data-driven landscape, organizations are increasingly relying on advanced analytics to drive decision-making. However, handling complex, nested JSON data in NoSQL databases like Amazon DynamoDB poses significant challenges for data transformation. This blog delves into a robust and scalable architecture for transforming DynamoDB’s complex JSON data into a structured format within a data lake. By leveraging AWS services such as AWS Glue, AWS Lambda, and AWS DataBrew, this solution offers a streamlined approach to data transformation, providing key insights for businesses seeking to optimize their analytics capabilities.
Amazon DynamoDB is a fully managed NoSQL database service that delivers fast, predictable performance with seamless scalability. However, as data grows, organizations often need to perform complex analytics on the data stored in DynamoDB. Transforming this data into a structured format, like tabular or Delta tables in a data lake, can significantly enhance query performance and enable advanced analytics.
Also Read: Why Data Transformation is the Platform for Actionable Insights
This blog outlines a scalable architecture for efficiently transforming complex JSON data from AWS DynamoDB into a structured format. Leveraging multiple AWS services, this solution is unique and provides valuable insights for organizations seeking similar transformations.
Addressing Key Challenges in Data Transformation
AWS’s NoSQL database, DynamoDB, is economical due to its pay-per-request model, making it a popular choice for many new applications. However, efficiently transforming the nested JSON data stored in DynamoDB into a structured format for advanced analytics is challenging. This blog provides a comprehensive, step-by-step solution to address this challenge, offering insights not readily available in existing documentation.
Also Read: Feature Scaling for ML: Standardization vs Normalization
Problem Statement
Flattening complex, nested JSON data in DynamoDB can be cumbersome, often requiring dedicated applications to parse and separate key-value pairs into rows and columns. Traditional methods are time-consuming, processing data row by row. In contrast, using AWS DataBrew significantly accelerates this process, completing it in under 10 minutes.
Architecture Overview
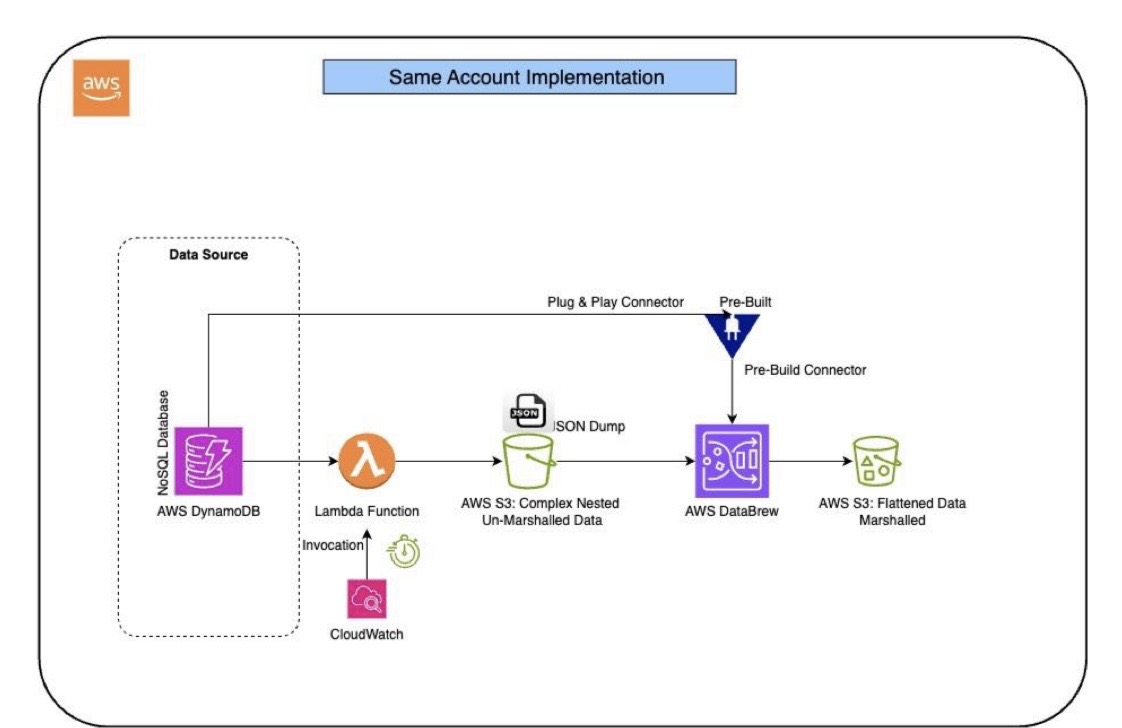
Architecture 1: Same AWS Account Implementation
- DynamoDB: Multiple tables reside in the same AWS account.
- AWS Glue or Lambda: Fetch tables from DynamoDB and store them in the raw zone on an S3 path.
- AWS DataBrew: Fetch data into a dataset and apply transformations using the NEST-UNNEST function to flatten nested JSON into a structured format with rows and columns.
Also Read: Up Your Analytics Game with Data Transformation
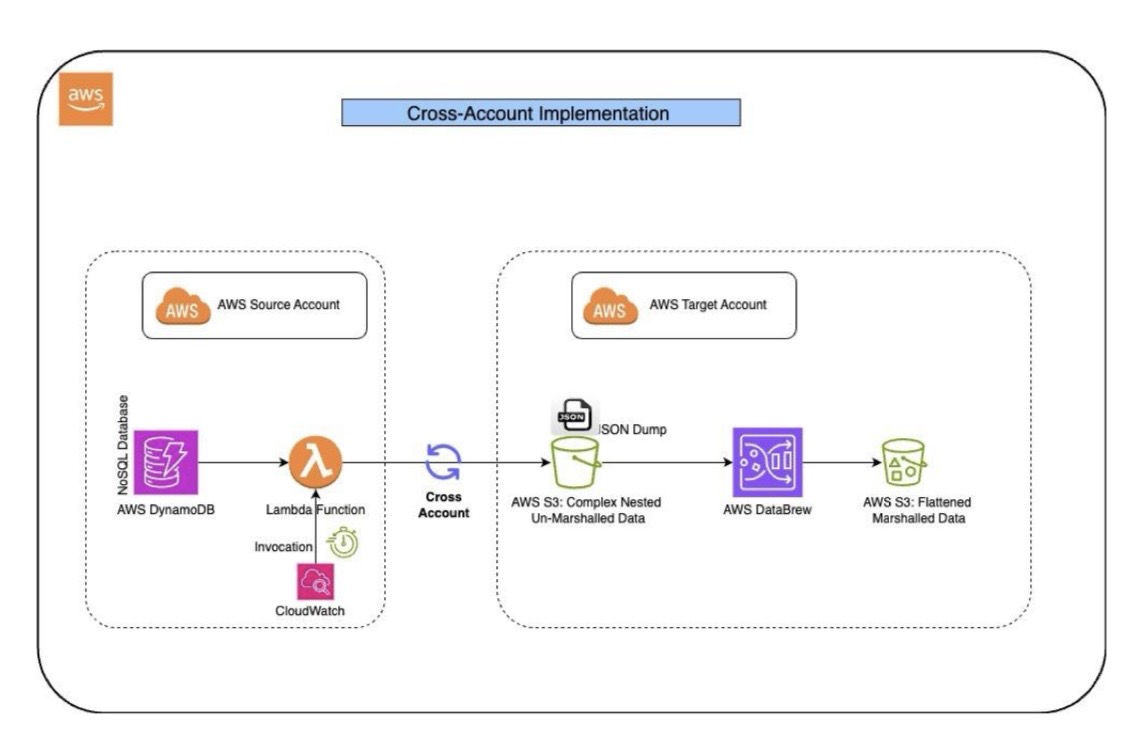
Architecture 2: Cross AWS Account Implementation
- DynamoDB: Multiple tables reside in a different AWS account.
- Cross-Account Role: Establish a cross-account role for AWS Glue or Lambda to access the cross-account DynamoDB.
- AWS Glue or Lambda: Fetch tables from DynamoDB and store them in the raw zone on an S3 path.
- AWS DataBrew: Fetch data into a dataset, apply the NEST-UNNEST transformation, and write the structured data into S3 in Parquet format.
- AWS Athena: Query and report on the structured data stored in S3.
Detailed Solution
Step 1: Fetching Data from DynamoDB
- Same AWS Account: Use AWS Glue or Lambda to access DynamoDB tables directly and export the data to an S3 bucket in the raw zone.
- Cross AWS Account: Establish a cross-account role allowing AWS Glue or Lambda to access DynamoDB tables in a different AWS account and export the data to an S3 bucket in the raw zone.
AWS DataBrew Pre-built Connector for DynamoDB: AWS DataBrew can connect directly to DynamoDB within the same account using a pre-built connector, simplifying data fetching by eliminating intermediate steps like using AWS Glue or Lambda. However, this pre-built connector does not work with cross-account data pipelines.
Step 2: Data Transformation with AWS DataBrew
- Data Ingestion: Use AWS DataBrew to ingest raw data from the S3 bucket into a dataset.
- Transformation: Apply the NEST-UNNEST function within DataBrew to flatten nested JSON structures into a tabular format, converting key-value pairs into columns and rows.
- Job Creation: Create a DataBrew job to automate the transformation process and output the structured data in Parquet format, stored in the S3 bucket.
Step 3: Querying and Reporting
- AWS Athena: Utilize AWS Athena to query the transformed data stored in S3, enabling advanced analytics and reporting with its efficient query capabilities on structured data.
Benefits of the Solution
- Efficiency: The transformation process using AWS DataBrew is significantly faster than traditional methods, reducing processing time from hours to minutes.
- Scalability: The architecture is designed to handle large volumes of data, leveraging the scalability of AWS services.
- Cost-Effectiveness: Utilizing DynamoDB’s pay-per-request model and S3’s cost-effective storage makes the solution economical.
- Simplicity: AWS services like Glue, Lambda, and DataBrew simplify implementation, requiring minimal custom development.
- Enhanced Connectivity: Direct connection of AWS DataBrew to DynamoDB via a pre-built connector streamlines data fetching and transformation processes.
Conclusion
Transforming complex nested JSON data from DynamoDB into a structured format is crucial for advanced analytics. This blog presents a scalable architecture leveraging AWS services to achieve this transformation, providing a guide for organizations looking to enhance their data analytics capabilities. By covering both same-account and cross-account implementations and highlighting AWS DataBrew’s capabilities, this article serves as a comprehensive resource for data transformation on AWS.
Also read: Unleashing the Power of Generative AI with Amazon Bedrock
Also read: AWS re:Invent 2024: What to Expect?
Also read: Optimizing AWS Glue Efficiency: Enhancing Performance with File Consolidation Strategies




