
Feature Scaling for ML: Standardization vs Normalization
Reading Time: 19 min
Anand Kidder

Mar 31,
2022 |
Posted in
Data Services
The big idea: Data today is riddled with inconsistencies, making it difficult for machine learning (ML) algorithms to learn from it. Organizations need to transform their data using feature scaling to ensure ML algorithms can quickly understand it and mimic human thoughts and actions. The article takes readers through the fundamentals of feature scaling, describes the difference between normalization and standardization and as feature scaling methods for data transformation, as well as selecting the right method for your ML goals.
Why it is important:
The accuracy of machine learning algorithms is greatly improved with standardized data, some of them even require it. The only way to standardize data is a process called feature scaling. Determining which feature scaling method—standardization or normalization—is critical to avoiding costly mistakes and achieving desired outcomes.
What’s ahead:
This article will help you understand data preparation for machine learning by covering the following topics:
- The role ML plays in organizations today
- What ML can do for different industries
- 4 levels of learning in ML
- Data-related challenges in ML
- What is feature scaling, its significance, types, and applications
- Selecting between standardization and normalization as feature scaling methods
- Popular scalers used for feature scaling data
The Power of Machine Learning
Technology has always been a great supplement to knowledge workers, but we are finally seeing it keep pace with actual human intelligence. Machine learning is a branch of artificial intelligence (AI) and computer science which focuses on the use of data and algorithms to imitate the way that humans learn, gradually improving its accuracy. Although we are still far from replicating a human mind, understanding some of the mental processes like storage, retrieval, and a level of interpretation can delineate the human act of learning for machines. As a result, ML will be able to inject new capabilities in our systems like pattern identification, adaptation, and prediction that organizations can use to improve customer support, identify new opportunities, develop customized products, personalize marketing, and more. Also, companies can unlock a world of possibilities when they hire Java developers skilled in machine learning.
With the big opportunities ML presents, it is no wonder the top four insurance companies in the US use machine learning. eCommerce is another sector that is majorly benefiting from ML. A classic example is Amazon, which generates 35% of its revenues through its recommendation engine. A manufacturing organization can make its logistics smarter by aligning its plans to changing conditions of weather, traffic, and transit emergencies. DHL has joined hands with IBM to create an ML algorithm for intelligent navigation of delivery trucks on highways.
Machine learning is powerful because it has the potential to solve real-world problems like spam, fraud, demand forecasts, personal assistance, and customer service. Some ways that different industries use ML to deal with their day-to-day operational challenges are listed below:
| Industry | ML Application | Capabilities |
| Pharmaceuticals | Patient Finder | Identify patients showing similar symptoms as other patients for faster diagnoses. |
| Treatment Pathway | Map diseased patient progress from one state to another while going through a series of therapies. | |
| Predictive Modeling | Predict the effectiveness of drugs that are planned for a launch and identify possible anomalies. | |
| Insurance | Anomaly Detection | Detect anomalies in the applications to predict and prevent financial fraud. |
| Ecommerce | Recommendation Engines | Analyze buyer behavior to support product recommendations to increase the probability of purchase. |
| Social Media Provider | Personalized Feeds | Analyze user activities on a platform to come up with personalized feeds of content. |
| Automobiles | Self-driving support | Recognize inconspicuous objects on the route and alert the driver about them. |
The Power is in Data
The data that is used to train the ML models carries all the power. It can be used for training, validating, and testing models to enable algorithms to make intelligent predictions. The accuracy of these predictions will depend on the quality of the data and the level of learning that can be supervised, unsupervised, semi-supervised, or reinforced.
- Supervised learning: When inputs and outputs are clearly labeled in the data used for training
- Unsupervised learning: A type of algorithm that learns patterns from untagged data. An example of unsupervised learning is the detection of anomalies in data
- Semi-supervised learning: combination of supervised and unsupervised learning. It uses a small amount of labeled data and a large amount of unlabeled data. This type of learning is often used in language translations where a limited set of words is provided by a dictionary, but new words can be understood with an unsupervised approach
- Reinforced learning: Provides a defined process with clear rules to guide interpretations. Robots and video games are some examples
Data Challenges in Machine Learning
Data plays a significant role in ensuring the effectiveness of ML applications. However, working with data is not always simple. Considering the variety and scale of information sources we have today, this complexity is unavoidable. Here are a couple examples of data challenges in the healthcare industry:
A simple dataset of employees contains multiple details like age, city, family size, and salary – all measured with different metrics and follow different scales. While the age of a patient might have a small range of 20-50 years, the range of salary will be much broader and measured in thousands. If we plot the two data series on the same graph, will salary not drown the subtleties of age data?
Traditional data classifications were based on Euclidean Distance which means larger data will drown smaller values.
Scan through patient health records and you will encounter an overwhelming variety of data ranging from categorical data like problems, allergies, and medications, to vitals with different metrics like height, weight, BMI, temperature, BP, and pulse.
Plotting these different data fields on the same graph would only create a mesh that we will struggle to understand.
To tackle the problem of data differences, we need to enable data transformation. Data differences must be honored not based on actual values but their relative differences to tune down their absolute differences. For this, we use feature scaling, a technique to scale up or down data points to bring them in the same range.
Feature Scaling: Standardization vs Normalization
Feature scaling can be done using standardization or normalization depending on the distribution of data. Let us dig deeper into these two methods to understand which you should use for feature scaling when you are conducting data transformation for your machine learning initiative.
Selecting between Normalization & Standardization
| Type of Algorithm | Feature Scaling Approach |
| Principle Component Analysis | Standardization |
| K-Nearest Neighbors | Normalization |
| Support Vector Machine | Standardization |
| LASSO and Ridge regressions | Standardization |
| Logical Regression | Normalization |
| Neural Networks | Normalization |
Standardization is a method of feature scaling in which data values are rescaled to fit the distribution between 0 and 1 using mean and standard deviation as the base to find specific values. The distance between data points is then used for plotting similarities and differences. Below is an example of how standardizations brings data sets of different scale into one single scale:
| Raw Data Set #1
|
Standardization
|
Raw Data Set #2
|
Standardized
|
| 30 | 0.17
|
10000000
|
0.04
|
| 40 | 0.22
|
220000000
|
0.80
|
| 50 | 0.28
|
14000000
|
0.05
|
| 60 | 0.33
|
30000000
|
0.11
|
Standardization is used for feature scaling when your data follows Gaussian distribution. It is most useful for:
- Optimizing algorithms such as gradient descent
- Clustering models or distance-based classifiers like K-Nearest Neighbors
- High variance data ranges such as in Principle Component Analysis
Whether the data is categorical, numerical, textual, or time series, normalization can bring all the data on a single scale. Thus, it is often used for scoring in training or retraining a predictive model. Every time the model is trained with novel data, the mean and standard deviation values are updated based on the combination of historical data and new data. Another application of standardization is in laboratory test results that suffer from inconsistencies in lab indicators like names when they are translated.
But what if the data doesn’t follow a normal distribution? It must be normalized. One of the most common transformations is the below formula:
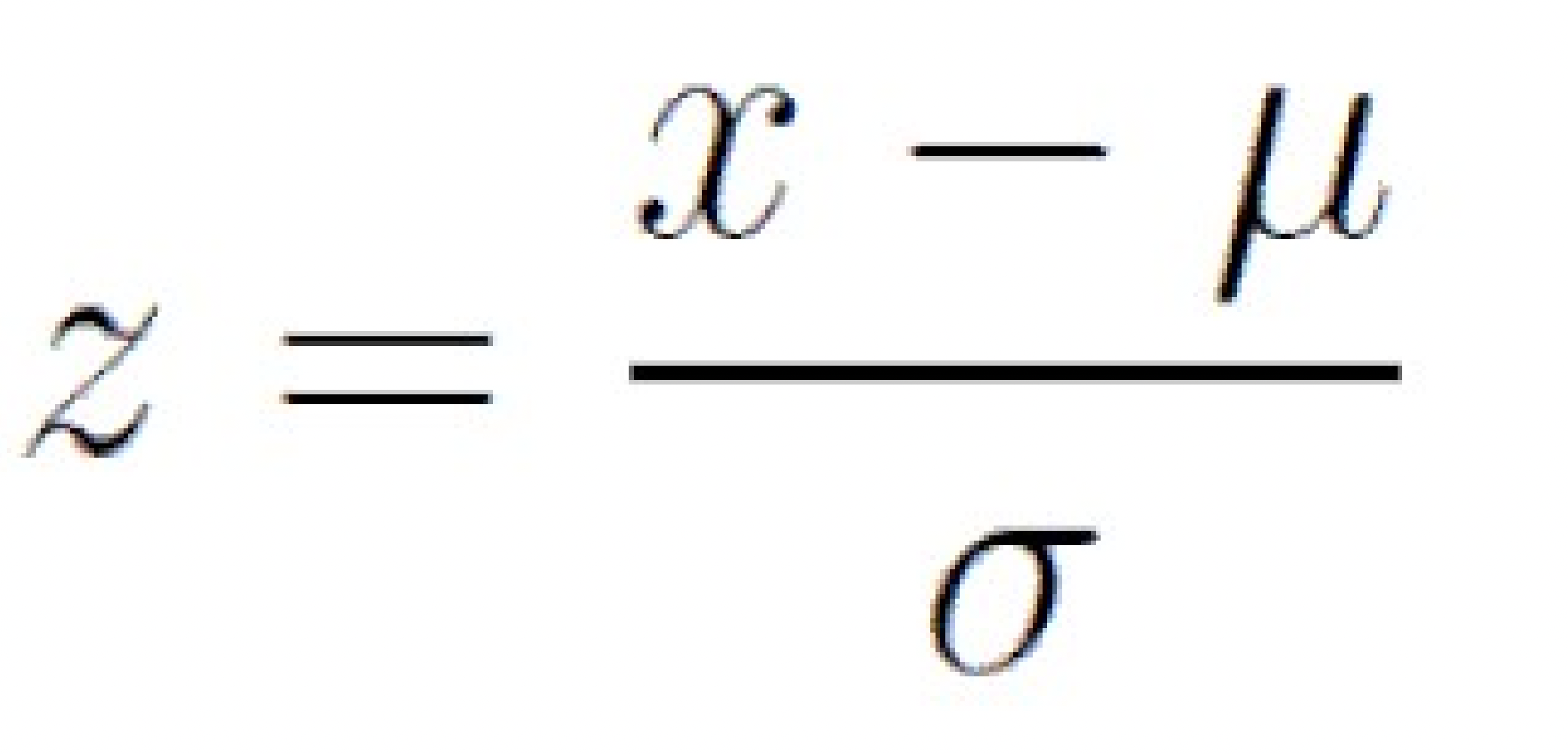
But what if the data doesn’t follow a normal distribution? It must be normalized.
The approach that can be used for scaling non-normal data is called max-min normalization. The rescaling is once again done between 0 and 1 but the values are assigned based on the position of the data on a minimum to maximum scale such that 0 represents a minimum value and 1 represents the maximum value. Another normalization approach is unit vector-based in which the length of a vector or row is stretched to a unit sphere in a visual format. This is most suitable for quadratic forms like a product or kernel when they are required to quantify similarities in data samples. Normalization is often used for support vector regression. This approach can be very useful when working with non-normal data, but it cannot handle outliers.
A good application of normalization is scaling patient health records. Patient health records are normally obtained from multiple sources including hospital records, pharmacy information systems, and lab reports. Inconsistencies are possible when combining data from these various sources. Data normalization can help solve this problem by scaling them to a consistent range and thus, building a common language for the ML algorithms.
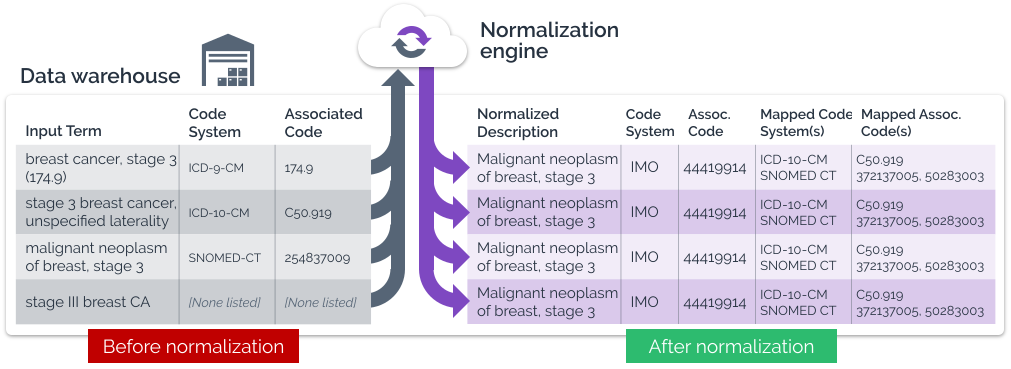
Source: Imohealth
The feature scalers can also help in normalizing data and making it suitable for healthcare ML systems in different ways by:
- Rescaling local patient information to follow common standards
- Remove ambiguity in data through semantic translation between different standards
- Normalize EHR data for standardized ontologies and vocabularies in healthcare
Popular Scalers Used for Feature Scaling
Feature scaling is usually performed using standard transformers like StandardScaler for standardization and MinMaxScaler for normalization. In Python, you have additional data transformation methods like:
- BoxCox transformation used for turning features into normal forms
- YeoJohnson transformation that creates a symmetrical distribution using a whole scale
- Log transformation which is used when the distribution is skewed
- Reciprocal transformation which is suitable for only non-zero values
- Square root transformation that can be used with zero values
Data Transformation for ML
Data holds the key to unlock the power of machine learning. Feature scaling boosts the accuracy of data, making it easier to create self-learning ML algorithms. The performance of algorithms is improved which helps develop real-time predictive capabilities in machine learning systems. Perhaps predicting the future is more realistic than we thought.
Machine Learning coupled with AI can create exciting possibilities. To learn more about ML in healthcare, check out our white paper. For more on machine learning services, check out Apexon’s Advanced Analytics, AI/ML Services and Solutions page or get in touch directly using the form below.”
Also read : AWS Solutions for Complex JSON Data Transfer from Amazon DynamoDB to Data Lake




