
How Amazon HealthLake Makes Sense of Health Science Data
Reading Time: 26 min
Sahil Sawant

Sep 14,
2021 |
Posted in
Cloud
Pop quiz: Do you know how much data was created in 2020?
The answer, unsurprisingly is a LOT! Every human on average created 1.7 MB of data per second. To put that into context on a global scale, that equates to around 13.4 billion MB of data created in the same amount of time that it takes the Earth to travel 18.5 miles through space.
When we add up all the data created in 2020, the total is a staggering 912 quintillion MB, according to a recent industry report … in case you are curious, a quintillion is 1 followed by 18 zeroes.
When you also consider that the majority of the world’s total data creation has come in the last couple of years, then the amount of data available is hard to comprehend. When you add the global healthcare event from 2020 into the mix, then the importance of accurate and effective data becomes even more critical to understand. And if we take that idea one step further, then the continued digitization of society is going to make data an even more valuable commodity than before.
If we look at the figures for stored data, here were about 44 zettabytes of data stored on the cloud in 2020, compared to 4.4 zettabytes in 2019. This number is expected to increase and by 2025, a research report said, there could be more than 200 zettabytes of data on the cloud.
Every industry will be leveraging data to gain the insights needed to optimize their business strategies, but it can be argued that the healthcare and life sciences sector have not only the most to gain but the most to lose from not understanding or implementing data sources. For that reason alone, this blog will consider both why the healthcare industry is primed to take advantage of data and the challenges that companies face to do it right.
Effective Healthcare Needs Data
Healthcare is a multi-dimensional industry, whose main aim is prevention, diagnosis, and treatment of health-related issues. And data is the key to effective wellness and patient well-being.
The caveat is that healthcare providers and associated life sciences companies face numerous challenges on their data-related journey.
For example, it can take weeks or months to go through individual health records and manually identify and extract key clinical information. On a very basic level, this includes standard elements within the healthcare system itself – diagnoses, medications, procedures, provider or physician notes, associated documents, digital images attached to patient forms, to name but a few.
The increased adoption and integration of an Electronic Health Record (EHR) enables decision-making by providing enormous data. The problem for the healthcare sector is that most of this information is unstructured. In other words, it is data that does not follow a pre-defined model or organizational framework.
One of the reasons for the prevalence of unstructured data is we can record data in many formats. In addition, structured data requires the adherence to certain options – a drop-down menu and checkboxes, say. It should come as no surprise that this can fall short of capturing data of complex nature.
We cannot record non-standard data regarding a patient’s key lifestyle factors, socioeconomic data, clinical suspicions, patient preferences and other related information in any other way but in an unstructured format.
However, we still need to extract data from this unstructured format. This can be very time consuming, requiring special tools and highly specialized teams. In most cases, this would make this a tricky task for companies – a clinician, for example, can take anywhere between three and eight hours to manually extract data from either a single or group of patients.
In addition, there are newer standards like Fast Healthcare Interoperability Resources (FHIR), processes that were designed specifically to describe data formats and elements via an application programming interface (API) for exchanging electronic health records. These digital tools help define common formats.
The thing to remember is that you still need the technology to automate and make the data usable and scalable for the workloads. To date, none of these data operations can be used to manage patients or predict their outcomes. These are all challenges that can be traced back to data infrastructure and formats.
And as healthcare data becomes a more critical part of the process, the requirement to understand and act on these insights will become a defined priority. . In the last decade, for instance, we have witnessed a digital transformation in the health care industry with organizations capturing huge volumes of patient information every day.
All this data needs to come together in an organized way at the point of care. The question that needs to be asked is not only how do we do that but what are the digital tools that will make sense of the data.
Getting the Full Picture
There is a consensus that Machine Learning and AI could be the answer. If we accept that patient wellness is determined by the data available, then tools that ingest or dissect the information and provide a full picture of the patient’s medical history will both unlock new insights and enable more informed decision making by the healthcare provider.
Amazon HealthLake is such a tool.
Launched at AWS re:invent 2020, Amazon HealthLake is a HIPAA-eligible service for healthcare companies, health insurance, and pharmaceutical companies to store, transform, query, and analyze health data consistently in the AWS cloud at a petabyte-scale. This service essentially removes the heavy lifting of health data analysis to provide a complete view of each patient’s medical history in a secure, compliant, and auditable way.
Health Care and Life Sciences customers can now aggregate all their disparate health information across various styles and formats into a centralized AWS data lake. In addition, Amazon HealthLake makes it easy to import your data from on-premises to AWS. Importantly, both structured and unstructured data can be stored, including but not limited to clinical notes and lab results.
By using machine learning models, the service will normalize the information by tagging the key dates, medical descriptors, and events like medications, procedures, and diagnosis. Amazon Healthlake then appends those data transformations to the original clinical message, which means that the data remains consistent. And all that data is fully indexed, so you can quickly and easily search and analyze all the health information.
Widely used clinical models predicting the risk of something, for example, such as heart disease are built from highly available but simple templates that have less than 30 data points. By contrast, an EHR has at least 300,000 data points available for each patient, including the medical notes.
Health data is notorious for being messy, incomplete and inconsistent. In addition, it’s often stored in on-premises and legacy systems. And this data is also sequential, making context an important part of clinical decisions.
For instance, when a lab note comes in or there’s a medical image generated or any other form of medical data, they all have different contexts which makes the large amount of information disparate. But when it is pulled altogether, it tells a holistic story.
Disparate Information Delays Effective Healthcare
To better understand the choke points being experienced by healthcare providers, we need to look at an actual use case. For the record, the problem we have identified is not exclusive to healthcare, and remains a common challenge in all industries, namely that the data relating to patients or from other aspects of healthcare tends to be siloed in different systems.
In this case, a doctor needs medical information about a patient or a group of patients. This information can be gathered from either a patient administration system, an electronic healthcare record system or a lab-test system. Three potential sources of information, three different access points.
That would be irritating in one organization, but when the patient’s data is spread across multiple environments, it becomes even more frustrating.
Whenever a patient has been admitted for care in a clinic or hospital, the attending doctor must go through required data from multiple organizations, all of which can be in the same or different formats. This is where the aforementioned FHIR format is a tremendous help in terms of interoperability, mainly as all the disparate data is brought together to form a complete record of the patient’s medical history.
Most clinicians can cope with these different data sources, purely because that is the system that they work in. The ongoing issue that many are now experiencing is that there is just so much data being generated from so many different systems that integrating it into a patient wellness plan or diagnosis means that this information might just as well live in a spreadsheet or as learned knowledge.
Crucially, as medical data has increased in volume, it has increased the accuracy of the analysis. The flip side of this coin is that the more data you have to analyze, the time taken to get the required insights has also increased.
Amazon HealthLake is the Missing Link
With that in mind, what clinicians really need is both a single point of data and a tool that can compartmentalize everything they need into one access point. The graphic below is a good example of how Amazon HealthLake can provide what they require to do their job effectively.
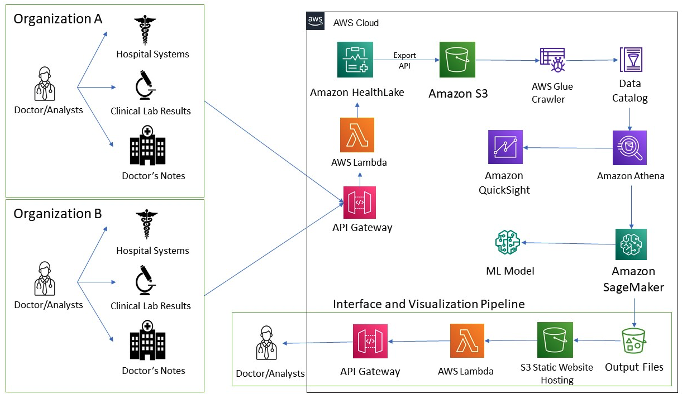
Integrating Amazon HealthLake
Amazon HealthLake helps structure the data from various systems, then tags each record to keep an updated index on every patient. The platform also brings recognized medical concepts like temporality (the relationship between blood pressure and the passage of time, say) – or negation (when something didn’t happen, like a patient without hypertension) together and dissects the relevant information.
To understand how Amazon HealthLake ties all the pieces of a patient puzzle together, we should look at how the data is presented to healthcare providers or clinicians:

 Example of Clinical Sample Note, using Amazon HealthLake
Example of Clinical Sample Note, using Amazon HealthLake
If you look at the four sentences from the clinical sample note above, the patient is a 62-year-old female with a history of Type 2 diabetes. These four sentences may be short, but they contain a lot of valuable information. Pair these sentences with the number of messages coming in everyday from other patients and the actionable insights become a valuable diagnostic tool.
Additionally, this note shows the end reader how to identify medical conditions such as s Type 2 diabetes and hypertension (HTN). It also identifies abbreviations like blood pressure (BP), timestamps when BP was taken, and highlights that there is no previous history of HTN. All this information is then automatically structured and put in a JSON object that is then appended to the original text, thereby providing a detailed view of patient history and current requirements.
The complex medical data available is seen in the JSON image below.

JSON Image, Amazon HealthLake
As you can see, we have access to the notes, the data that is being extracted and the structured object itself.
The JSON file pulls together the notes, the data that is being extracted and, finally, the structured object. For each of the medical elements that are extracted, there will be a unique tag where the text will also identify where the text is the sentence – such as begin offset and offset – and then provide a confidence score to show the transparency of matching that medical entity in the text. These behind-the-scenes intricacies are a critical part of ensuring that the end reader has everything they need to know.
Let’s take the first instance of the date, which is 14th January 2019. That’s pulling the data out of the text. And then the tool has a concept of relationship type. So, it takes that date and now relates it to the diagnoses, which you can see is now nested and labelled Type 2 diabetes.
Once the system has all the requisite data, then a complete view of a patient’s health information can be created. This also allows the healthcare provider to construct a data lake for all patients and encounters, with the graphic below shows how this information can be displayed, organized by different attributes such as medications, tests, procedures, labs, and diagnoses for every patient encounter.
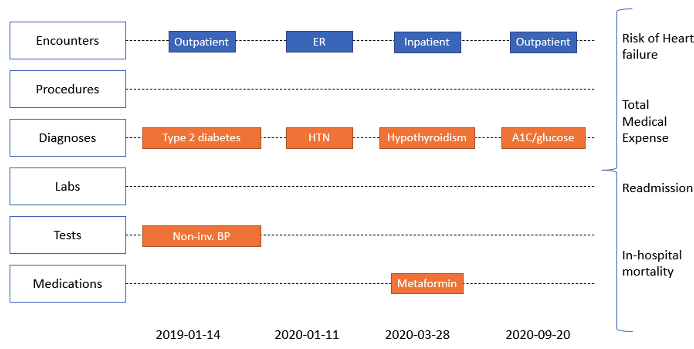
Patient Overview
As a result of gathering the disparate data in one place, the entire medical database can be searched and queried using standard medical terms. Amazon Athena is introduced here as an interactive query service, which makes it easy to analyze data in Amazon S3.
Where Amazon HealthLake can take digitization of healthcare data to the next level is in the integration of advanced analytics and machine learning.
By applying the concepts of continuous learning, healthcare providers can predict or analyze population health trends. This allows for services such as Amazon SageMaker to be introduced, with the tool able to predict the spread of disease or other markers that are relevant to the information a clinician requires on a day-to-day basis. This level of insight can then be applied to an individual patient or an entire population of patients.
Taking Health Data to the Next Level
Adding Amazon HealthLake to the roster of services offered by AWS will help to deliver new ways for end users to interact with healthcare systems. Having this level of detail and granularity improves the efficiency and throughput for a wide variety of use cases, such as medication reconciliation, revenue, cycle management, and population and health analytics.
There is also considerable scope for healthcare providers and life sciences companies to support initiatives such as the 21st Century Cures Act – designed to make healthcare more affordable and accessible – and the “Digital Front Door,” which aims to improve the health outcomes by helping patients receive perfect healthcare from the comfort of their home.
One key element to remember is thar machine learning is going to become more mainstream in the not-so—distant future. That will empower more companies to apply the technology to not only their business optimization strategies but also the services that they can offer end users. Healthcare and life sciences have traditionally relied on data and actionable insights to deliver the wellness outcomes that patients and providers require, and digitalization is the logical path for these industries to take.
Data always matters, but being able to access the information when you need it most is a minimum requirement in the connected society. For clinicians and patients, it could quite literally be the difference between life and death.
Click here to learn more about Apexon’s digital health expertise. Alternatively, contact us to learn how Apexon’s digital engineers can help you advance your toughest digital health challenges using the form below.




