
Mastering Serverless Data Analytics with AWS Glue and Amazon Athena
Reading Time: 10 min
In the fast-paced world of data engineering and advance analytics, efficiently processing and analyzing vast amounts of data is crucial. AWS Glue and Amazon Athena are two powerful tools in the AWS ecosystem that enable serverless data processing, making it easier and more cost-effective to manage and query data at scale.
In this blog, we will explore what AWS Glue and Amazon Athena are, how they work, and how you can leverage them to unlock the full potential of your data infrastructure.
AWS Glue: ETL Made Easy
AWS Glue is a comprehensive managed service designed for extract, transform, and load (ETL) operations. This service streamlines data preparation and loading for analytics purposes. By automating complex tasks associated with data integration, AWS Glue empowers data engineers to efficiently configure, oversee, and coordinate ETL workflows.
Also Read: Optimizing AWS Glue Efficiency: Enhancing Performance with File Consolidation Strategies
Key Features of AWS Glue:
- Serverless Architecture: AWS Glue is serverless, meaning you don’t need to provision or manage servers. It automatically scales to handle your data processing needs, reducing operational overhead and costs.
- Integration with Other AWS Services: AWS Glue integrates seamlessly with other AWS services such as Amazon S3, Amazon Athena, Amazon EMR (Elastic MapReduce), and AWS Lambda, enabling you to build comprehensive data pipelines.
Amazon Athena: Interactive Querying of Data in S3
Amazon Athena complements AWS Glue by providing a serverless query service for analyzing data directly in Amazon S3 using standard SQL. It eliminates the need for infrastructure management and setup, allowing you to run ad-hoc queries on large-scale datasets stored in S3.
Key Features of Amazon Athena:
- SQL Queries: Athena supports standard SQL queries, making it accessible to analysts and data scientists familiar with SQL. You can query data directly in S3 without needing to load it into a separate database.
- Schema-on-Read: Athena uses schema-on-read, which means it interprets the structure of your data at query time. This flexibility allows you to query diverse datasets without predefined schemas.
Also Read: Unleashing the Power of High-Performance Computing In Banking and Financial Services – Part 1
Benefits of Using Glue and Athena Together
- Streamlined Data Analysis: Glue automates data preparation tasks, saving you time and effort, while Athena allows for quick and easy querying of the prepared data.
- Cost-Effective: Both Glue and Athena offer a serverless pay-per-query model, meaning you only pay for the resources you use.
- Scalability: They can handle massive datasets efficiently, making them ideal for organizations dealing with big data.
By leveraging Glue and Athena together, you gain a powerful combination for unlocking valuable insights from your data, ultimately leading to better decision-making in various real-world scenarios.
Integrating AWS Glue with Amazon Athena
Integrating AWS Glue with Amazon Athena allows you to use Glue’s data catalog as a metastore for Athena queries, simplifying the management of your data and queries. Here’s how you can integrate AWS Glue with Amazon Athena:
1. Set Up AWS Glue Data Catalog
- Create a Database: In the AWS Glue console, navigate to Databases and create a new database if you haven’t already. This database will hold the metadata for your tables.
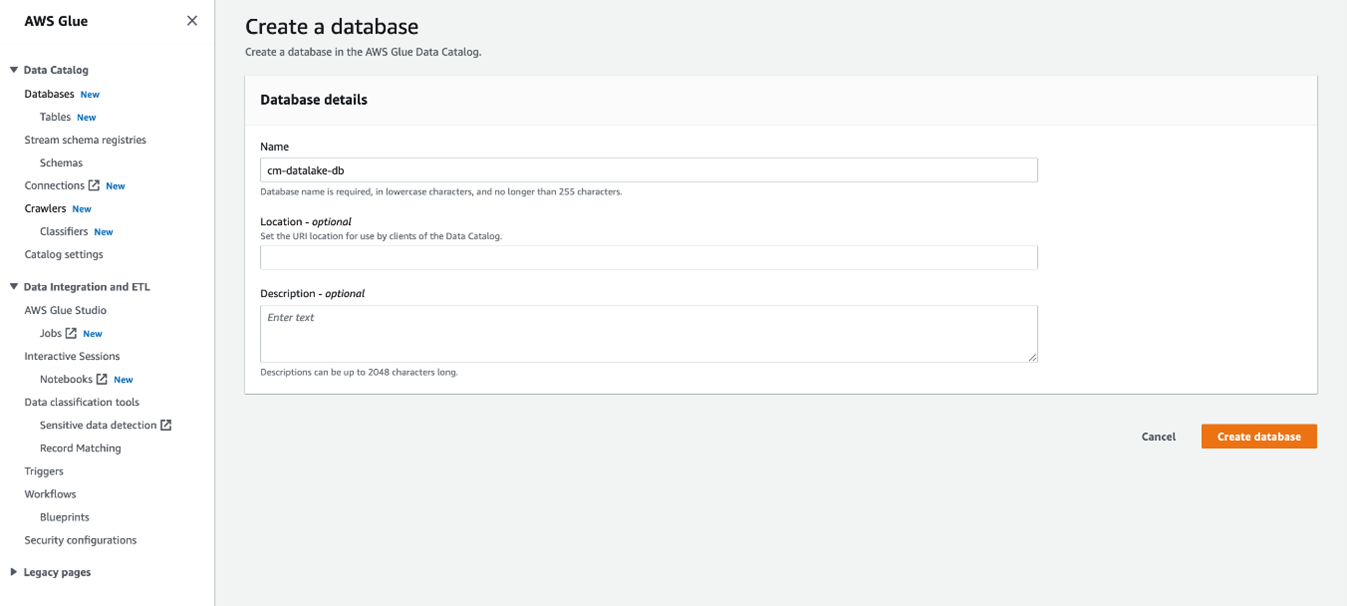
- Crawl Your Data: Crawlers in AWS Glue automatically discover your data and populate the Glue Data Catalog with table definitions. Set up a crawler to crawl your data sources (S3 buckets, databases, etc.) and create table definitions in the Glue Data Catalog.
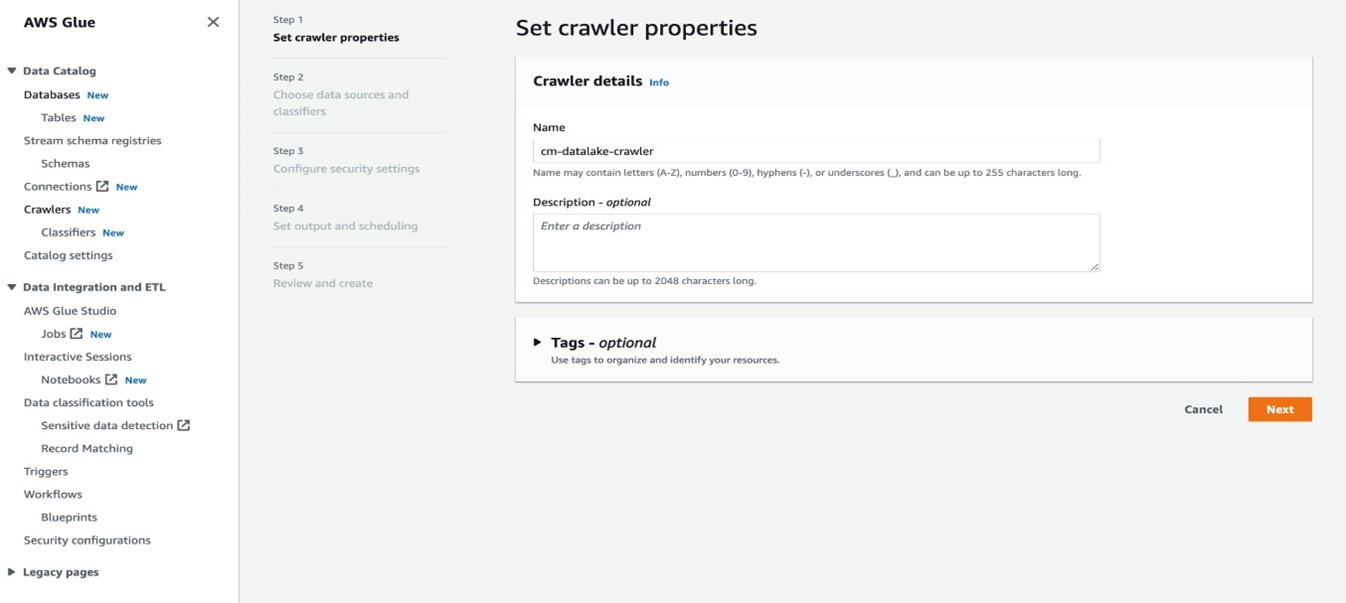
Also Read: Cost Optimisation for AWS SageMaker in GenAI Real-Time Inference Endpoints
2. Grant Permissions
Ensure that AWS Glue and Amazon Athena have the necessary permissions to access each other’s resources. You can do this by setting up appropriate IAM roles with the required policies.
- IAM Role for AWS Glue: Create an IAM role that allows AWS Glue to access the Glue Data Catalog and your data sources (e.g., S3 buckets).
- IAM Role for Athena: Create an IAM role that allows Athena to access the Glue Data Catalog and the data stored in your S3 buckets.
3. Configure Athena to Use AWS Glue Data Catalog
- Open Athena Console: Navigate to the Athena console in the AWS Management Console.
- Choose Data Catalog: When creating a new query in Athena, choose the data catalog (database) that corresponds to your AWS Glue Data Catalog.
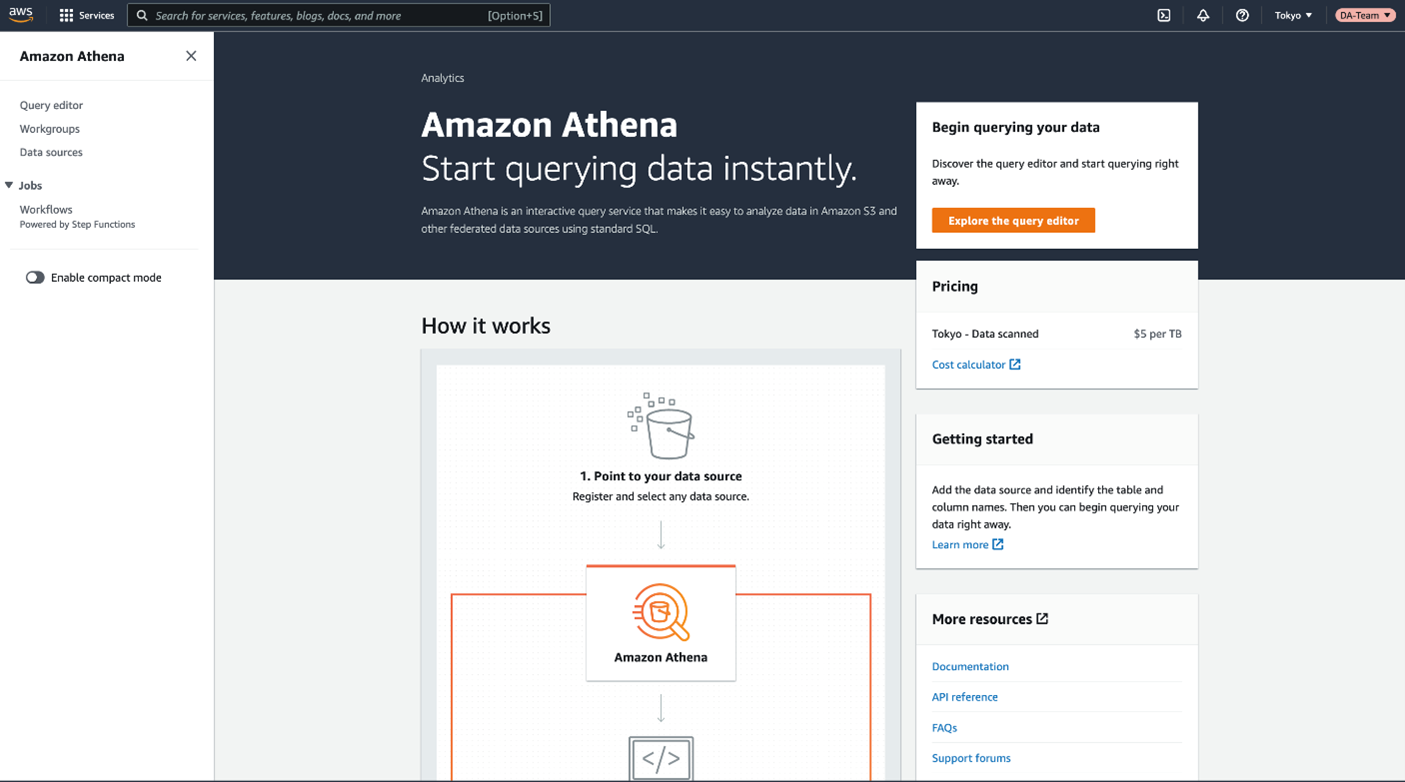
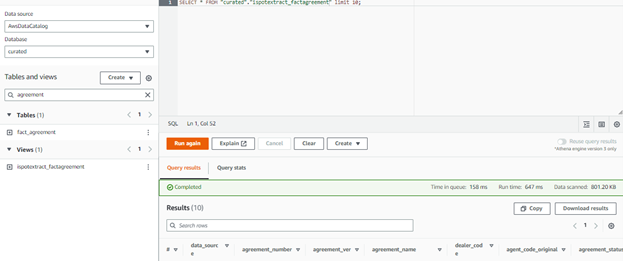
4. Query Data in Athena
Once you’ve configured Athena to use the Glue Data Catalog, you can query your data using standard SQL syntax. Athena will reference the table definitions stored in the Glue Data Catalog when you run queries.
Conclusion
AWS Glue and Amazon Athena together provide a robust and flexible solution for serverless data processing and analytics in the cloud. By utilizing their capabilities, organizations can streamline their data workflows, accelerate time-to-insight, and make data-driven decisions with confidence. Embrace the power of AWS Glue and Amazon Athena to transform your data analytics initiatives and unlock new possibilities for your organization.
Tools/AWS Services Used:
- AWS Glue
- AWS Athena
- AWS IAM
Also read: AWS re:Invent 2024: What to Expect?
Also read: Mastering Serverless Data Analytics with AWS Glue and Amazon Athena
Also read: Optimizing AWS Glue Efficiency: Enhancing Performance with File Consolidation Strategies




