
Optimize Performance & Cut Cost with AWS Autoscaling Services
Reading Time: 14 min
Dirghayu Dave

Jul 7,
2020 |
Posted in
Cloud
One of the best ways of getting the most out of the AWS Cloud platform is autoscaling, and it is both free and easy to implement. Autoscaling provides better fault tolerance, better availability, and better cost management. When any infrastructure components are not healthy enough to serve a request, autoscaling detects the issue and replaces it with a healthy component. In this way, autoscaling quickly scales up and down to meet traffic demands while keeping costs within budget.
Autoscaling helps organizations:
- Meet the traffic requirement on-demand and scale accordingly.
- Adjust scaling group capacity through scheduled actions on autoscaling groups.
- Reduce resources when not required and save costs.
- Increase application availability by deploying across availability zones.
With AWS, there are several services that help autoscaling the infrastructure components and reduce management associated with scaling. They are mediated through CloudWatch, the AWS monitoring and observability service, which provides data and actionable insights to monitor your application and infrastructure, and to respond to system-wide performance changes and resource utilization. For instance, CloudWatch provides up to one second visibility of metrics, 15 months of data retention (metrics), and the ability to perform calculations on metrics. This allows digital engineering teams to perform historical analysis, for cost optimization, for instance. On top of the specified metrics, teams can create alarms and alarm trigger the autoscaling policy to perform predefined steps, either to scale out or scale in.
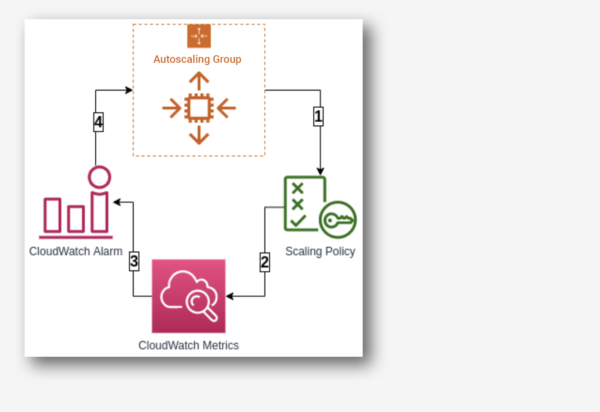
Autoscaling Services on AWS Cloud Platform
1. EC2 Instance Auto Scaling
EC2 instance autoscaling helps us to keep the correct number of EC2 instances available to handle incoming traffic requests for the application. We can create an EC2 autoscaling group, which is a collection of EC2 instances. In that group, we can specify a minimum, making sure that the group never goes below a specified size. We can also specify a maximum number of EC2 instances, which ensures that the group never goes above the specified size. This keeps capacity within a minimum and maximum range, and it ensures that your autoscaling group has EC2 instances specified in the desired capacity. Autoscaling also allows us to configure scheduled actions that can change the minimum, maximum, and desired auto-scaling group capacity at a specified time.
EC2 instance autoscaling allows for the configuration of scaling policies that will scale up or down according to the policy to increase or decrease EC2 instances in your infrastructure.
There are two types of scaling: manual, in which we can attach and detach EC2 instances from the autoscaling group, and dynamic scaling, where we can define how to scale the autoscaling group capacity in response to the incoming request or changing demand in terms of specific resource utilization. This allows us to configure policies that can take care of scale-up and scale-down and acts according to the policy for factors such as the number of requests, CPU, and memory utilization.
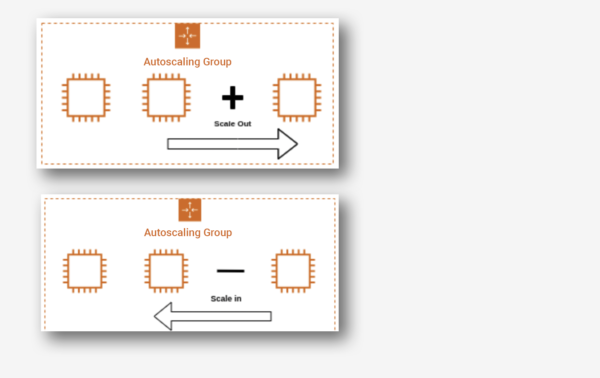
Below are the three types of dynamic scaling policies.
- Target-tracking – This policy will increase or decrease the autoscaling group’s current desired capacity based on the target value for the specific metric. This policy maintains the capacity to match specified target metrics like CPU or memory utilization. Let’s assume that you have set 60% utilization of your autoscaling group, the target-tracking policy will add or remove EC2 instances to meet the specified utilization.
- Step Scaling – This policy increases or decreases the current capacity of the autoscaling group based on a set of scaling adjustments (EC2 instances) that vary based on the size of the alarm breach. Let’s assume that the autoscaling group has three stages for tracking CPU utilization: the first alarm would be triggered when 40% is reached and would add one EC2 instance, the second when 60% is reached and two EC2 instances are added, and the third if 80% is reached when three EC2 instances would be added.
- Simple Scaling – This is a simple scaling policy option that increases or decreases the current autoscaling group capacity based on a single scaling adjustment. Here we can add one EC2 instance when specified alarm breaches.
EC2 autoscaling provides on-demand instance scaling and spot fleet instance autoscaling, where we can automatically increase or decrease the current capacity of the spot fleet based on the demand. It can launch (scale out) or terminate (scale in), within the specified range.
2. ECS Container Service Auto Scaling
Elastic Container Service (ECS) Auto Scaling works on container published CloudWatch metrics like CPU and memory usage. It increases or decreases the desired capacity of container tasks in ECS service automatically. You can use CloudWatch metrics to scale out (add more tasks) to handle a high degree of incoming requests and scale in (remove tasks) during low utilization.
ECS Auto Scaling allows us to configure policies like target tracking, step scaling, and scheduled scaling actions.
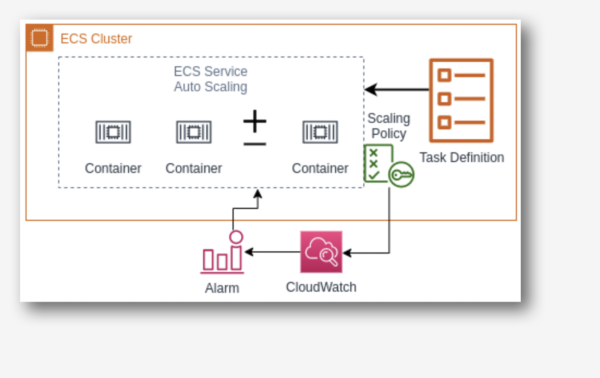
3. RDS Storage Auto Scaling
Amazon Relational Database Services (RDS) for MariaDB, MySQL, PostgreSQL, SQL Server, and Oracle support storage autoscaling, with zero downtime RDS storage autoscaling automatically scale the backend storage volume attached to RDS database in response to growing database size.
RDS monitors current storage consumption and scales storage capacity up when current consumption reaches near to the actual provisioned size, without affecting current database operation and disturbing current database transections.
4. Aurora Auto Scaling
AWS Aurora autoscaling adjusts the number of Aurora replicas dynamically. You can define the scaling policy, and Aurora acts accordingly. It scales Aurora replicas to handle a sudden increase in the database connectivity or the workload. As and when database connections or workload decreases, Aurora Auto Scaling removes unwanted Aurora replicas automatically, meaning customers are not charged for the unwanted replica instances.
Just as we were able to define scaling policies in other services, so we can define them in Aurora Auto Scaling, and it also allows us to configure the minimum and the maximum number of Aurora replicas that can be managed. Aurora Auto Scaling is available for both of the Aurora engines MySQL and PostgreSQL.
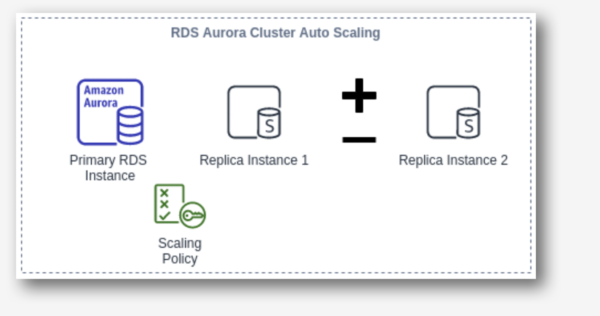
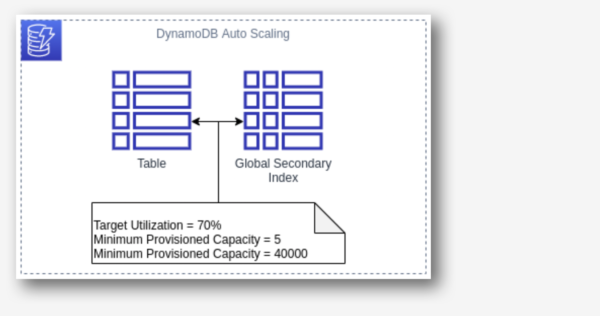
5. DynamoDB Auto Scaling
The most difficult part of the DynamoDB workload is to predict the read and write capacity units. If an application needs a high throughput for a specific period, it is not necessary to over-provision capacity units for all the time. Amazon DynamoDB Auto Scaling dynamically adjusts provisioned throughput capacity on your behalf, in response to actual incoming traffic request patterns.
As and when the workload decreases, application autoscaling decreases the provisioned throughput capacity units, so that customers do not pay for any unnecessary capacity.
With DynamoDB Auto Scaling, we can create scaling policies on the table or global secondary index. We can specify within the scaling policy whether we want to scale read capacity or write capacity (both), and the minimum and maximum provisioned capacity unit settings for the table or index.
Prime Your Infrastructure For Autoscaling
In order for these AWS autoscaling services to function as they should, organizations need to ensure they have:
- Specified application user session state and persistence when using EC2 instances.
- Tested, monitored, and tuned their autoscaling strategy to ensure that it functions as expected.
- Decision-making logic in place that evaluates these metrics against predefined thresholds or schedules, and decides whether to scale out or scale in.
- Service-specific limits in place before configuring autoscaling.
- While using EC2 autoscaling, that teams have specified cooldown time, which application to start up and are ready to serve in a defined time.
Want to learn more about maximizing your cloud-native development environment? Share your toughest digital challenge with us, and we’ll solve it for you. Use the form below to get in touch.




