
Optimizing AWS Glue Efficiency: Enhancing Performance with File Consolidation Strategies
Reading Time: 6 min
In today’s digital age, data is integral to decision-making processes and the efficient operation of various business activities. As the volume of data generated each day continues to rise, it becomes imperative to manage and process this data effectively to extract valuable business insights. This is where AWS Glue proves invaluable, providing a serverless data integration service that simplifies the preparation and loading of data for analytics.
One frequent challenge is dealing with a large number of small files that can impact the performance of data processing jobs. Therefore, we will explore different approaches to merging small files into larger ones using AWS Glue to significantly enhance job performance and reduce costs.
Also Read: Mastering Serverless Data Analytics with AWS Glue and Amazon Athena
Benefits of Merging Small Files
Merging multiple small files into larger ones offers several benefits:
- Reduced Overhead: Processing a large number of small files incurs overhead in terms of opening and closing files, fetching metadata, reading data, and managing other resources. By integrating small files into larger ones, the overhead is minimized, leading to faster job implementation.
- Improved Parallelism: When processing large files, AWS Glue can leverage parallel processing capabilities to divide the workload across multiple nodes, resulting in improved performance.
- Cost Savings: With fewer files to process, the amount of resources required for data processing in AWS Glue is reduced, leading to cost savings in terms of compute and storage.
How to Merge Small Files Using AWS Glue
1. groupFiles and groupSize Parameters
To improve the performance of ETL tasks in AWS Glue, it is crucial to configure job parameters effectively. One important aspect is the grouping of files within an S3 data partition. Setting the groupFiles parameter to inPartition allows Glue to automatically group multiple input files. Additionally, the groupSize parameter can be set to define the target size of groups in bytes.
For example:
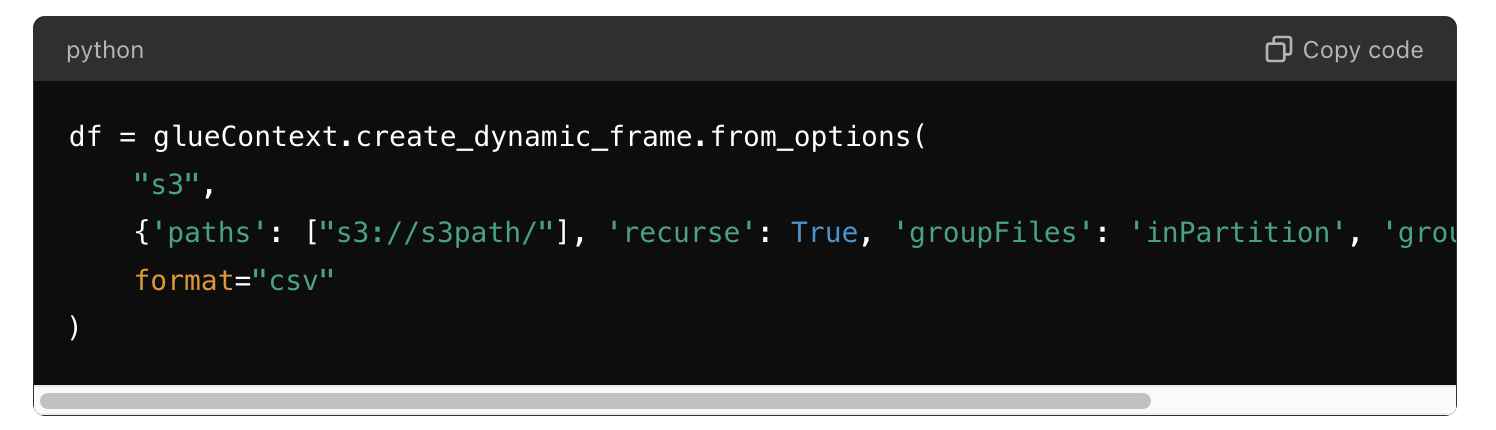
Setting the groupSize to 209715200 defines the grouping size of data in one partition to read as 200MB, enhancing data partitioning speed for data processing.
Also Read: AWS Solutions for Complex JSON Data Transfer from Amazon DynamoDB to Data Lake
2. Coalesce or Repartition
To improve the efficiency of data writing, use repartition or coalesce before saving it to S3.
- Coalesce: Uses existing partitions to reduce data shuffling. It results in partitions with different amounts of data but performs better than repartition while decreasing the number of partitions.
- Repartition: Creates new partitions and performs a full shuffle of data, resulting in roughly equal-sized partitions. It is generally suggested when increasing the number of partitions.
For example:

By managing the number of output files, we can effectively manage file sizes for data handling processes.
Also Read: Optimizing Costs with AWS: Why Every Business Should Consider It
Conclusion
Merging small files into larger ones in AWS Glue can significantly improve job performance, reduce runtime, and optimize costs. By consolidating small files, we can streamline data processing, enhance parallelism, and achieve substantial cost savings. As data continues to grow in volume and complexity, leveraging AWS Glue to efficiently manage and process data is essential for staying competitive in today’s data-driven environment.
Tools/Technology:
- AWS Glue
- AWS S3




