
Why Vector Databases Matter in Designing AI-Enabled Solutions
Reading Time: 9 min
What are Vector Databases
Traditional databases excel at managing structured data, using predefined schemas and exact matches for retrieval. However, the AI realm heavily relies on unstructured data—text, images, audio, and sensor readings—which these systems struggle to handle effectively.
Vector databases offer a solution.
Vector databases are specialized systems designed to handle and retrieve high-dimensional data represented as vectors. These vectors capture not just the data itself but also the relationships and similarities between data points. This enables vector databases to excel at semantic search, finding data points with similar meanings or characteristics, even if they are not identical.
Also Read : Unleashing the Power of Azure AutoGen and AI Bots
Types of Vector Databases
- Memory-Mapped Databases: These store data in memory, providing incredibly fast retrieval speeds ideal for real-time applications.
- Disk-Based Databases: These store data on disk drives and offer larger storage capacities than memory-mapped databases.
Key Features
Vector databases come with a unique set of features that make them highly valuable for building and running AI applications, including:
- High-Dimensional Data Support: Ability to handle complex data structures.
- Similarity Search: Efficiently find data points with similar characteristics.
- Blazing-Fast Retrieval Speeds: Quick access to relevant data.
- Scalability: Adaptability to growing data volumes.
- Integration with AI Frameworks: Seamless compatibility with AI tools and platforms.
Also Read : Applying Quantum Computing and AI in Healthcare and Financial Services
Vectors can be generated from various types of raw data using machine learning methods such as feature extraction algorithms, word embeddings, or deep learning networks.
Capabilities:
Vector databases play a pivotal role in several advanced AI functionalities:
- Retrieval-Augmented Generation (RAG): Vector databases enhance the capabilities of large language models by providing efficient retrieval mechanisms. In RAG, the model first retrieves relevant documents or data points from the vector database and then generates responses based on this enriched context. This process significantly improves the relevance and accuracy of generated content, especially in domain-specific applications.
- Data Preprocessing and Feature Engineering: Effective AI solutions often require transforming raw data into a structured format that can be efficiently processed. Vector databases support advanced preprocessing techniques such as tokenization (breaking text into meaningful units), stemming (reducing words to their root form), and feature engineering (creating vectors that capture essential characteristics of the data).
- Metrics for Vector Similarity: The ability to measure similarity between vectors is a core functionality of vector databases. Metrics like cosine similarity (measuring the cosine of the angle between two vectors) and Euclidean distance (measuring the straight-line distance between two points in multi-dimensional space) are commonly used. The choice of metric depends on the specific application and data type, allowing for flexible and precise similarity searches.
- Query Optimization: Vector databases optimize search queries to retrieve relevant results efficiently. Techniques like k-nearest neighbor (KNN) searches, which identify the closest data points in vector space, enhance query performance. This optimization ensures that AI applications can quickly and accurately find relevant data, even in large and complex datasets.
Also Read : Adaptive AI Use Cases in Financial Services, Healthcare, and Retail
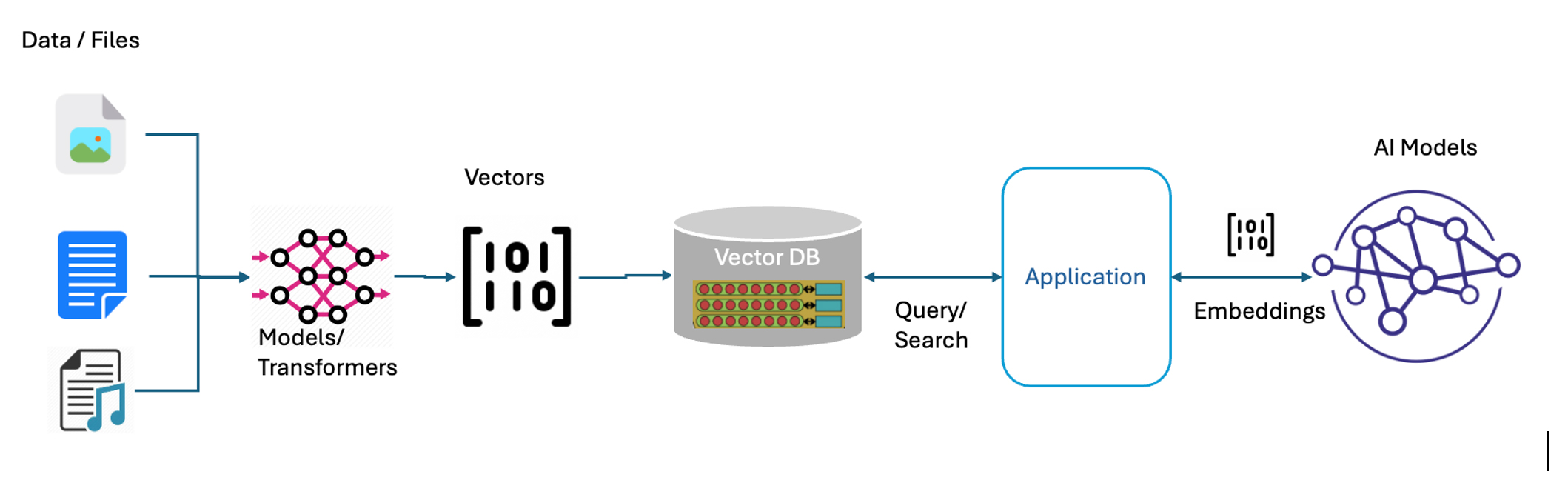
Use Cases
Vector databases unlock a range of exciting possibilities in the AI world:
- Image and Video Recognition: Enhance accuracy in identifying objects, faces, and scenes.
- Recommendation Systems: Provide personalized recommendations based on user behavior and preferences.
- Chatbots and Virtual Assistants: Improve understanding of user intent and provide more relevant responses.
- Fraud Detection: Detect fraudulent activities by analyzing patterns and identifying anomalies.
- Natural Language Processing (NLP): Understanding semantic relationships between words can improve sentiment analysis, text summarization, and machine translation.
Options:
Several open-source and commercial vector database options are available, each with its strengths and weaknesses:
- Pinecone.io
- Milvus
- Faiss (Facebook AI Similarity Search)
- Annoy (Approximate Nearest Neighbours)
- Relational databases with Vector support (PostgreSQL)
Also Read : Adaptive AI: Unlocking Benefits and Overcoming Challenges
Choosing the Right Vector Database
Selecting the ideal vector database for your project depends on specific needs. Consider the following factors:
- Data Size and Storage Requirements: Memory-mapped databases might suit smaller datasets, while disk-based databases are better for larger volumes.
- Performance Requirements: For real-time responses, a memory-mapped database is ideal. Otherwise, a disk-based database might suffice.
- Scalability Needs: Assess anticipated data growth and choose a solution that can scale efficiently.
- Open-Source vs. Commercial: Open-source options offer flexibility but may require more configuration, while commercial solutions typically offer easier setup and support.
Vector databases offer immense potential for building more efficient, scalable, and accurate AI solutions. Embrace the future of AI data management with the power of vector databases!
Conclusion
Vector databases represent a significant advancement in data management for AI-enabled solutions. By efficiently handling high-dimensional data and facilitating powerful semantic searches, they address the limitations of traditional databases in managing unstructured data. Their capabilities enhance various applications, from image recognition and recommendation systems to fraud detection and natural language processing.
Looking ahead, vector databases’ potential is vast. As AI evolves, these databases will become even more integral, driving innovations in real-time data processing, personalized user experiences, and advanced analytical capabilities.




