AS CLOUD BECOMES UBIQUITOUS, EFFECTIVE MANAGEMENT IS KEY
With the on-demand nature of cloud computing touching every aspect of our lives, the requirements for effective migration and integration become increasingly important.
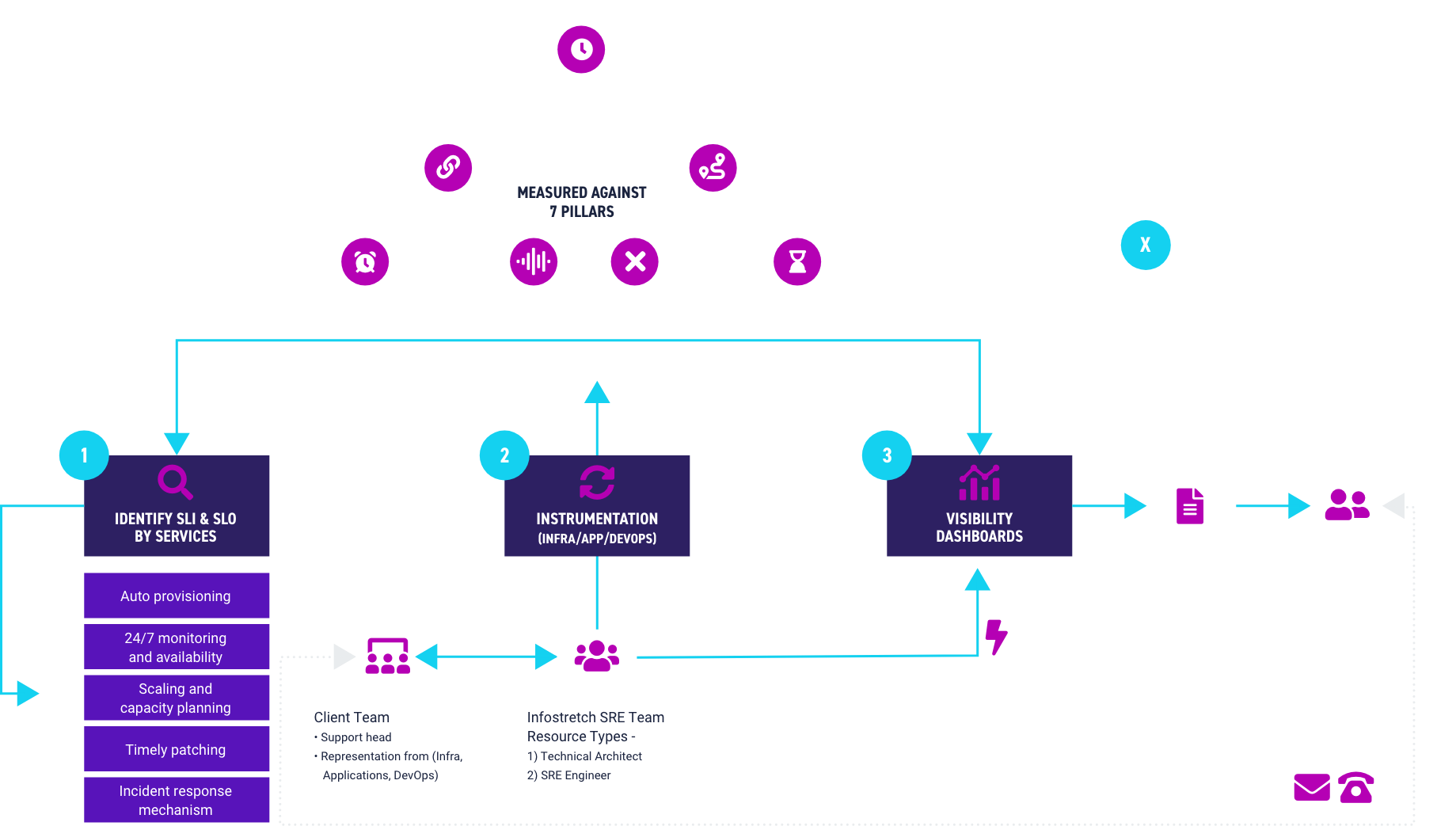
More than 85% of companies will have a cloud-first attitude by 2025, according to Gartner. And the organizations that embrace cloud will have to take account of both the digital workloads they create and the operations they will serve.
Even more critical is that business leaders understand exactly what is required from cloud solutions, with availability, reliability, and customer engagement opportunities all part of the cloud puzzle. Simply put, a poorly managed cloud environment can impact not only time-to-market but also potential revenue, brand reputation and customer satisfaction. In today’s hypercompetitive marketplace, threats to any of these can be hard to overcome.